

This article focuses on how to load data in ML.NET Model using the API. Loading the data properly is the first step in every Machine Learning project.
Machine Learning data is usually stored in files. CSV (Comma Separated File) for example is quite popular choice. But often data is stored in other data sources such as databases, JSON, XML or in-memory collections.
ML.NET provides an easy and effective way to load data from multiple sources. These data loaders can be accessed from the MLContext.Data property.
This guide will teach you how to leverage the power of ML.NET to load machine learning data from any source.
Let’s dive in.
Create the data model
ML.NET allows you to represent data models through classes. Most Machine Learning scenarios require an Input and Output data models. A data model can hold specific information on the problem you are trying to solve.
To explain things further let’s look at the Iris Dataset. Because it is one of the best-known datasets in the pattern recognition literature, it is easy to find and analyze.
Iris Dataset contains 3 classes of 50 instances each. And each class refers to a type of iris plant. Every instance has the following attributes:
- Sepal Length in cm
- Sepal width in cm
- Petal length in cm
- Petal width in cm
- Class:
- Setosa
- Versicolor
- Virginica
These attributes reveal the Data Model properties. Now, let’s create the InputModel class. But, before doing that, make sure to reference Microsoft.ML in your project. It contains the Microsoft.ML.Data namespace which in turn holds two very important attributes.
Load Data in ML.NET: the Data Model
public class ModelInput
{
[ColumnName("sepallength"), LoadColumn(1)]
public float Sepallength { get; set; }
[ColumnName("sepalwidth"), LoadColumn(2)]
public float Sepalwidth { get; set; }
[ColumnName("petallength"), LoadColumn(3)]
public float Petallength { get; set; }
[ColumnName("petalwidth"), LoadColumn(4)]
public float Petalwidth { get; set; }
[ColumnName("variety"), LoadColumn(5)]
public string Variety { get; set; }
}
This class defines four float properties representing the sepal and petal length as well as sepal and petal width in centimeters. Variety is a string property representing the Iris type. Here are the first twenty rows from the Iris dataset.
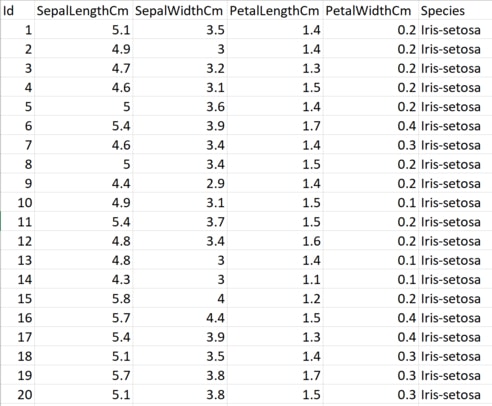
Float is the perfect type to describe the width and length in centimeters. And string fits for the Iris Species description. But why the data model is annotated with attributes?
As it turns out the attributes give ML.NET more information about the data model and the data source.
For example, because the data will be loaded from a CSV file, the LoadColumn attribute specifies the column index, and it is required only when you load the data from file.
File format such as CSV has the data separated by a comma. As a result, it creates data columns. So, to load the Species column from the file, you must set LoadColumn index to 5.
Please note the indexing starts from zero.
ColumnName attribute allows to specify the column name directly. However, if not specified the default behavior would kick in and will use the class members name as the column name.
Load Data in ML.NET
Machine Learning Data comes in all shapes and sizes. It can be a single large file, or even multiple files across different folders. And sometimes the complete data set can be loaded up in a memory collection.
ML.NET offers features to load the data from multiple sources easily.
Data Loading methods can be accessed from the mlContext.Data property.
All these methods return IDataView type introduced to .NET specifically for ML.NET. Similar to what IEnumerable<T> is for LINQ, the IDataView type is the fundamental component to the machine learning pipeline.
Binary Data Loader
Data saved in binary format is generally smaller in size then other formats. Working with binary files increase the performance as well.
var binaryData = mlContext.Data.LoadFromBinary("Iris.bin");This statement demonstrates how to load data in ML.NET from a binary file. If you want to try this code, you can load data from a file or an in-memory array and then use the following statement to save it.
using (FileStream fs = new FileStream("Iris.bin", FileMode.Create))
{
mlContext.Data.SaveAsBinary(myData, fs);
}Once, you have the file saved as .bin type, you can use the previous code example to load it in ML.NET.
Enumerable Data Loader
Although it is not a preferred way to store the data in memory, for a smaller data set this can be done using the LoadFromEnumerable method.
ModelInput[] inMemoryCollection = new ModelInput[]
{
new ModelInput
{
Petallength=1,
Petalwidth=5.1f,
Sepallength=3.5f,
Sepalwidth=0.2f,
Variety="Iris-Setosa"
},
new ModelInput
{
Petallength=7.7f,
Petalwidth=2.8f,
Sepallength=6.7f,
Sepalwidth=2.0f,
Variety = "Iris-Virginica"
}
};var enumerableData = mlContext.Data.LoadFromEnumerable<ModelInput>(inMemoryCollection);First, an in-memory data array is created. Then LoadFromEnumerable<T> method is executed which allows user to load data in ML.NET Machine Learning context.
Load Data in ML.NET from Text File
To load data in ML.NET from text file is quite simple. Especially if the file is in CSV format. Because the data model is already defined, we can simply call LoadFromTextFile<T>
var myData = mlContext.Data.LoadFromTextFile<ModelInput>("Iris.csv", hasHeader: true, separatorChar: ',');CSV file stands for Comma Separated File format. So, if you have a CSV file, first create a ModelInput class representing each row of the CSV. Then you can use this class as the generic parameter that LoadFromTextFile method requires.
Iris.csv follows the CSV format and therefore the separatorChar is set to comma. The file has header as well, but it doesn’t contain any useful information except column names. By setting hasHeader to true, the ML.NET Machine Learning context will skip the first line and start loading the data from the second.
var dataView = mlContext.Data.LoadFromTextFile("Iris.txt");LoadFromTextFile method has multiple overloads. Iris.txt is a file created by loading in-memory array and saved as a regular text file. Because of that it is enough to pass only the file path parameter. But if your file is not properly serialized, you can use one of the overloads.
Most of the time you will create the ModelInput class by hand. By typing the class in. This operation can be boring and repetitive since you need it every time you create a ML.NET model. Automated script can do this work for you.
Although creating an automated script is outside of the scope of this article, think about how you can create it. What I have is a small Console Application that I can run, and it will output the ModelInput class as a .cs file.
The file is produced as a result of the data source analysis. It inspects the column names and the data types. Then it simply maps them in a C# .cs code file, ready to be imported.
Create a Text Loader
CreateTextLoader method provided by ML.NET to load data through the MLContext is also very useful.
var loader = mlContext.Data.CreateTextLoader(new TextLoader.Column[]
{
new TextLoader.Column("SepalLengthCm", DataKind.Single,1),
new TextLoader.Column("PetalLengthCm", DataKind.Single,3),
new TextLoader.Column("Species", DataKind.String, 4)
},separatorChar: ',',hasHeader:true);
var data = loader.Load("Iris.csv");It allows you to specify the columns you wish to load. As well as column name, type, and the index of the column in the data source. Working with CSV files is quite easy. It’s obvious why it is one of the most used data sources.
Providing separatorChar and hasHeader parameters is very important, because it tells ML.NET how to load data from the source.
Load method has couple of overloads. In the example above, the Load method takes in the file path as a parameter. However, it can also allow multiple file paths to be provided as a data source.
Quite often a dataset can reside in various different files. Instead of merging them into one, ML.NET simply provides a way to load them as separate data sources.
Save Data
So far, we have seen how to load data in ML.NET using the API. What about saving?
ML.NET does allow saving data to disk as well.
In the next example I will demonstrate how to save an in-memory collection to a file using ML.NET API.
First, we need to load the data from the collection like so:
var myData = mlContext.Data.LoadFromEnumerable<ModelInput>(inMemoryCollection);As you already know LoadFromEnumerable return an IDataView instance. This instance can be used as a parameter to one of the following ML.NET context methods:
- SaveAsBinary saves the IDataView content as a binary file
- SaveAsText saves the IDataView as a regular file
SaveAsBinary example:
using (FileStream fs = new FileStream(_binFilePath, FileMode.Create))
{
mlContext.Data.SaveAsBinary(myData, fs);
}SaveAsText example:
using (FileStream fs = new FileStream(_txtFilePath, FileMode.Create))
{
mlContext.Data.SaveAsText(myData, fs);
}Depending on the file structure you wish to save your data to, SaveAsText offers many parameters to choose from. Thus, you can save the data as plain text file or CSV formatted file.
Data Filtering
Data is always messy. That’s the reality of it. Sometimes a value can be missing, or the format is not quite right. If for whatever reason you want to filter out some data points, ML.NET provides that functionality for you.
Filtering could prove to be very useful to provide some initial cleansing that the data needs. These filtering capabilities can be accessed through ML.NET Contexts Data property.
var filteredData = mlContext.Data.FilterRowsByColumn(data, "SepalLengthCm", 0, double.MaxValue);Imagine if there was a negative value inside the Iris data set. To be more precise inside SepalLengthCm column. Data points like this is not only useless but it can hurt the ML.NET model as well.
The right way of handling it, is to filter it out.
Missing Data is also a big problem. But ML.NET has a solution to that. A function called FilterRowsByMissingValues. It allows the user to specify the IDataView it wants to process, as well as the column.
var filteredData = mlContext.Data.FilterRowsByMissingValues(data, "SepalLengthCm");If there are column values that cannot be parsed this method will filter the row out. However, if this method wasn’t used, ML.NET will not be able to parse the value and assign a NaN value.
FilterByCustomPredicate is a method that is filtering out rows where the predicate returns false.
mlContext.Data.FilterByCustomPredicate<Iris>(filteredData,(iris)=>iris.SepalLengthCm>3);This example demonstrates how to use the method. Every single iris data point with SepalLengthCm lower than 3cm will be filtered out. The core difference between this method and the others is that here you can create quite complex data filtering predicate.
Methods to perform filtering based on different criteria:
- FilterRowsByColumn filters data based on value ranges of a given column.
- FilterRowsByKeyColumnFraction filters rows by the value of a KeyDataViewType column
- FilterRowsByMissingValues filters the data by dropping rows where any of the column values have a missing value
Load Data in ML.NET from Database
To load data from database source first you need a Database Provider. In the demo project we are using the database.sqlite file. Structurally the database is the same as the CSV file.
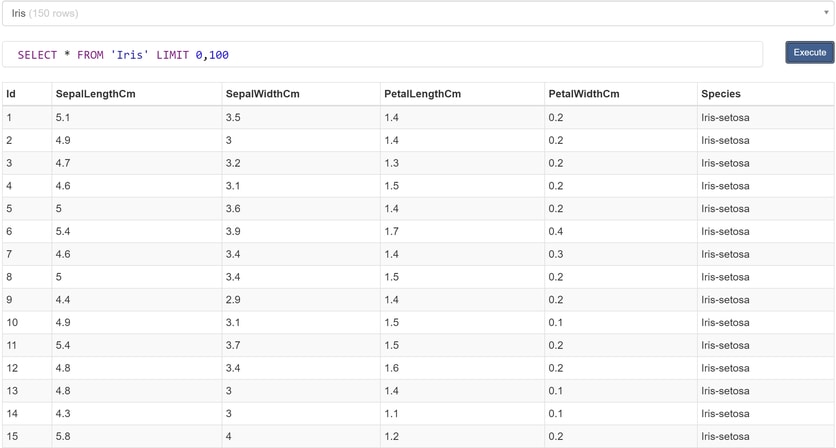
System.Data.SQLite is used as the database provided. You can install it from the Nuget Package manager. Most importantly is to know your database type and use the corresponding provider.
For example, you can also use System.Data.SqlClient. This namespace is the .NET Data Provider for SQL Server.
Next, we must set up the connection string and provide SQL command for execution.
var factory = DbProviderFactories.GetFactory("System.Data.SQLite");
var databaseSource = new DatabaseSource(factory, @"Data Source=database.sqlite", "SELECT * FROM 'Iris'");
var trainingView = mlContext.Data.CreateDatabaseLoader<ModelInput>().Load(databaseSource);
Iris is the table name, and the command retrieves all rows from it.
Having the database source set up, we are ready to load data in ML.NET IDataView type.
CreateDatabaseLoader method is provided by ML.NET to load data from database source. The database rows are mapped into ModelInput type. Even when loading data from a structured source such as a database, don’t forget to set up the desired column name and LoadColumn value. And it goes without saying that the field types must match. You will hit problems if you try to load a string type into a numeric field and vice versa.
Once the data is loaded into the IDataView type you can do additional filtering if needed. But as you can see the database provider also allows you to write SQL commands to filter data.
Load Data in ML.NET: IDataView
Every single data loading method we examined so far in ML.NET returns the IDataView type. Data in the pipeline travels inside this type. It was introduced in .NET specifically for ML.NET. This is the input and output of Query Operators.
Query Operators allows data loading and handling. In other words, this is the fundamental data pipeline type. Note that this type is an Interface. So far in the examples, we have used the pre-baked implementations. But interface type allows you to create custom implementation of your own from scratch.
IDataView is composable. This means that new views are created by applying calculations rather than copying data. This interface is just a virtual representation of the data. IDataView is not executing any data operations until the ML.NET Model starts training.
When a transformation is applied on the data view because it is read only, it creates a new view. As a result, IDataView is thread safe, improves performance, and reduces memory allocation.
ML.NET is also capable of handling big dataset. I am talking about a dataset that cannot fit into the memory all at once. The benefits from this type are endless. Although this is out of the scope for this article, we will talk more about this type as we move forward.
Preview Machine Learning Data
Machine Learning model implementation goes through an iterative cycle. You will see that each step from the process is visited again and again. This process is the result of the nature of the problems that Machine Learning is trying to solve.
Complex problems require you to adjust the data processing and the model repeatedly. Going through this cycle is necessary to ensure the best possible results.
To preview what data look like before or after pre-processing, ML.NET offers the Preview method which returns DataDebuggerPreview.
ColumnView and RowView are IEnumerable properties and contain the values in a particular column or row.
To preview the columns simply expand the ColumnView property like so:
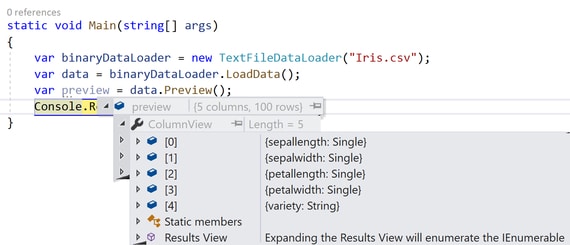
And, in to preview the data set content expand RowView property.
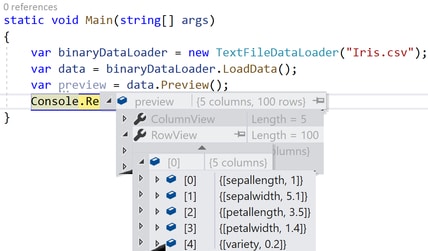
By default Visual Studio is showing the first 100 rows. This is the default option.
One very important note is to not use Preview in production code. This is because the intention behind this feature is for debugging process. As a result, it will reduce performance. So, make sure to delete this statement.
Conclusion
This article demonstrates various ways on how to load data in ML.NET Model using the API.
ML.NET has you covered for whatever scenario you find yourself in. Be that loading data from files (Text File, CSV, XML etc.), databases (Microsoft SQL, SQLite etc.), or in-memory arrays.
Filtering data is also possible. ML.NET offers couple of methods to filter data based on various criteria.
The cornerstone of data in ML.NET is the IDataView type. All data operations start and ends with this type. If for whatever reason the existing implementations are not enough, ML.NET allows you to create your own IDataView implementation. But make sure you use it because it is thread safe and improves the performance significantly.
It is important to remember that this type offers virtual representation of the data. Data is not loaded until the ML.NET Model executes the Fit method. Because of that, make sure that your data structure matches the one from the data source.
Now we know how to load data in ML.NET. The next article will cover all about data transformation. We will see what it is, and why we need to transform data. So, make sure to check out next week’s post on ML.NET.
Previous Post: How to build ML.NET Pipeline
Next Post: How to transform data in ML.NET
This tutorial on how to load data in ML.NET is available for download: