

Data comes in all shapes and sizes. The sole purpose of this article is to teach you how to transform data in ML.NET. Once you load the data, almost always there is a need to transform it.
ML.NET provides various types of transformers to transform the data from messy to clean. These data transformers can be accessed from MLContext instance Transforms property.
Data Transformation is the “unsexy” component of a data scientist’s job. But it is one of the most important and cool parts.
When we talk about Data Science we always want to start with a fancy wording like Artificial Intelligence and Machine Learning. Making predictions using complex algorithms on a wide variety of data. ML algorithms learn from the past. And it is our job to provide them with the best possible learning experience.
Why do we need to transform data in ML.NET?
A great learning experience adds value to the learner. Everybody is seeking high quality content to help them understand something they couldn’t before. Content that is easy to use and well-crafted. The entire learning experience should be purposeful, and put the needs of the learner first.
Machine Learning models require a good learning experience too. Therefore, making predictions depends on the data. And the data itself must be organized to ensure its analysis yield valuable insights.
Garbage In, Garbage out
Training algorithms need data. Vast amounts of data. And for the most accurate results, data needs to be in an analytics-ready state. In other words, the dataset must be of the highest quality.
But data doesn’t come that way. It can be convoluted and messy in its raw state. So, data transformation is required before training.
Data transformation is the process in which you take data from its raw state and transform it into data that is ready for analysis. This step makes sure that your data is of maximum quality before doing any type of analysis or training.
As a result, good data will provide you with valuable insights that will eventually empower data-driver decisions.
Transform Data in ML.NET
Data engineers almost always transform the data before using it in machine learning algorithms. If you end up feeding the data directly to the algorithm without proper cleaning, scaling, and normalizing, it will yield bad results. The output will be totally off, which is not acceptable.
ML.NET offers several ways to transform data from messy to clean. The main goal of this step is to identify and remove errors and any duplicate data. This in turn will enable the machine learning algorithm to make accurate decisions. Needless to say, this step is the most time-consuming step of the machine learning process.
There are many different statistical analysis and data visualization techniques you can use to inspect the data. These techniques can help guide you to make decisions on which cleaning operations you might want to perform on the dataset.
But before doing any sophisticated operations, there are couple that are fairly easy, and you should be performing on every single ML.NET project.
Clean data doesn’t have missing values, or values out of a pre-defined range.
For example, you cannot have string value where a numeric one is expected. Or negative value where a positive one must be provided.
If you have an age column, value like 1000 (years old) should not be permitted. Negative value is also not possible. Sometimes we do have a pre-defined enumeration for a column and values outside of that should be removed as well.
Bottom line, clean data is very important. And because of that ML.NET offers several ways to deal with messy dataset through stages that are called Data Transformers.
To transform data in ML.NET we will use a predefined extension method. ML.NET heavily relies on extension methods to make things glue together nicely.
Let’s look at a couple of examples.
Data Transform
The Data Transformation methods can be accessed on the MLContext instance. So, let’s create it first.
var mlContext = new MLContext();Then I will load up the dataset from a CSV file like so:
var data = mlContext.Data.LoadFromTextFile<InputModel>("Iris.csv",separatorChar: ',',hasHeader: true);And now we are ready to start our data transformation process.
Usually there are a couple of transformations necessary to bring data to a clean state. To do that ML.NET offers extensions methods. Those methods can be chained or glued together for ease of use.
Method Chaining is a technique in which methods are called on a sequence to form a chain and each of these methods return an instance of a class. These methods can then be chained together so that they form a single statement.
Because data transformation commands will be executed sequentially, method chaining fits perfectly in this scenario.
For example, we might want to remove missing data, then normalize or scale it. This can be done in a single statement using this technique.
Data Transformation Methods
ML.NET provides many ways to transform data. Some of them do require training data to calculate their parameters, but others don’t. Transform Data in ML.NET methods can be categorized in several groups
- Column mapping and grouping
- Normalization and scaling
- Conversions between data types
- Text Transformations
- Image Transformations
- Categorical data transformations
- Time series data transformations
- Missing values
- Feature Selection
- Feature Transformations
- Explainability Transformations
- Calibration Transformations
- Deep Learning Transformations
- Custom Transformations
The enumerated transformation groups above return classes that implement the IEstimator interface. Each class has an extension method called Append. This method returns EstimatorChain<T> class. Append is also defined as an extension method on that class as well.
If the last paragraph is a little bit confusing, don’t worry about it. It will become a lot more clear once we start creating chained data transformations.
Going over all types of transform data in ML.NET is out of the scope for this article. We will first examine some basic ones, then we will create more complex data transformation pipeline. Everything else we will cover in real-world project scenarios.
Method chaining allows us to create a pipeline. But before we create a complex pipeline, let’s look at some simple examples first.
Iris Dataset
For the needs of this tutorial, we will use the Iris dataset. If you don’t know how to load data, please refer to the previous post of this ML.NET tutorial series.
The Iris dataset structure:
We already know that Iris Dataset contains 3 classes of 50 instances each. And each class refers to a type of iris plant. Every instance has the following attributes:
- Sepal Length in cm
- Sepal width in cm
- Petal length in cm
- Petal width in cm
- Class: “Setosa”, “Versicolor”, “Virginica”
The data source file is a CSV (Comma Separated File) format. This file can be found inside the project itself.
Data Transform in ML.NET: Examples
SelectColumns method allows the user to choose which columns to keep and which ones to filter out. For example, if you have ID column in your dataset, you can use this method to remove it.
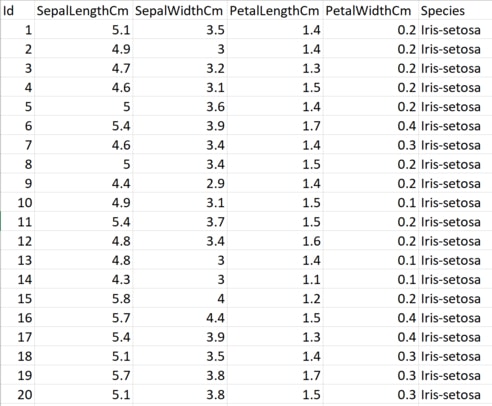
var pipeline = mlContext.Transforms.SelectColumns(new string[] { "SepalLength", "SepalWidth" });The execution of this transformation will not happen on this statement. These methods that transform data in ML.NET are executed once the Fit method is called.
var preview = pipeline.Fit(data).Transform(data).Preview();And here is the result
Just as we expected. The method filters out all columns except for: “SepalLength” and “SepalWidth”.
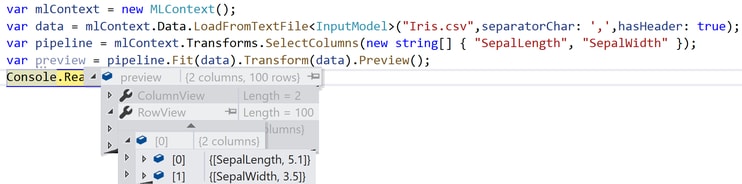
Concatenate method creates a new column which concatenates one or more input columns.
In this example we will concatenate “SepalLength” with “SepalWidth”. The expectations are that a new vector column is created with a length of two.
The transform data method requires a Column Name parameter, and an array of column names which needs to be concatenated. Obtained results are pretty self-explanatory. NewColumnVector is the new column ML.NET adds to our IDataView instance. And resulting value is a vector with length of two, containing the values from “SepalLength” and “SepalWidth” columns.
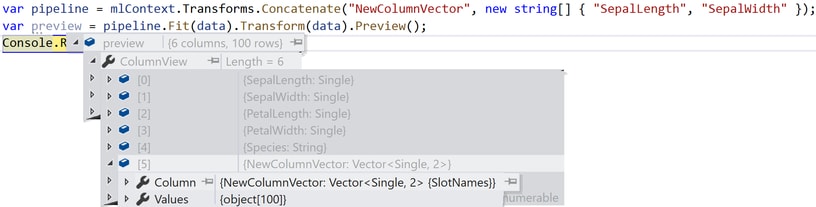
NormalizeMinMax allows data transformation that normalizes the targeted column based on the observed minimum and maximum values of the data.
Next example demonstrates the usage:
var pipeline = mlContext.Transforms.NormalizeMinMax("SepalLengthNormalized", "SepalLength");“SepalLengthNormalized” is the new column created from the normalized values of “SepalLength” column.
From the result you can see that the normalized value of “SepalLength” column is approximately 0.645. NormalizeMinMax normalize rows by finding min and max values. Then it creates a projection of that value between 0 and 1.
For now, it is enough to see how to use this method. Later on, we will see it real-world application.
Text Transformations
Let’s see how we can transform text data. The following data transformation techniques are useful for sentiment classification problems. Please note that you cannot present text data to the algorithm as strings. It needs to be quantified. In other words, the text needs to be transformed into numeric values.
This process will be heavily discussed in one of the real-world projects. Right now, the focus is on how to transform data in ML.NET.
For the needs of this example, I have created a SentimentModel class, with a single string property called “Text”.
public class SentimentModel
{
[ColumnName("Review")]
public string Text { get; set; }
}Next, I am creating in-memory collection of objects to couple of different Amazon product reviews.
var inMemoryArray = new SentimentModel[]
{
new SentimentModel(){Text="This book was not that good" },
new SentimentModel(){Text="I expected much more." },
new SentimentModel(){Text="If you want to learn c# this is the book for you. " },
new SentimentModel(){Text="The book is very interesting and easy to read."},
new SentimentModel(){Text="I've been trying to learn C# Razor Pages, and this has been very helpful." }
};
Finally, we can load the data like so:
var mlContext = new MLContext();var data = mlContext.Data.LoadFromEnumerable<SentimentModel>(inMemoryArray);NormalizeText method provided by ML.NET allows removal of unwanted punctuation marks and numbers. As well as changing the case of the strings.
var pipeline = mlContext.Transforms.Text.NormalizeText("NormalizedSentiment", "Review", keepPunctuations: false);
var preview = pipeline.Fit(data).Transform(data).Preview();
The preview method as discussed earlier allows me to check the transformations like so:
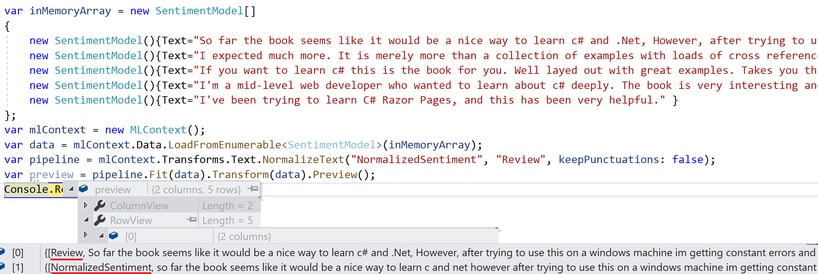
As you can see from the image provided, the resulting IDataView has all sentences in lower case and punctuation is removed.
Review is the input column and NormalizedSentiment is the output – the one that holds the result from this text transformation.
TokenizeIntoWords is another very useful method which splits the text into words.
var pipeline = mlContext.Transforms.Text.TokenizeIntoWords("Tokens", "Review");
var preview = pipeline.Fit(data).Transform(data).Preview();Review is set as the input column, and the result is being placed into the Tokens column. This resulting column represents an array of strings. Each string is a word that was found in the review text.
For example, if we have the following sentence:
“I expected much more”
the resulting array inside the Tokens column will be:
[“I”, “expected”, “much”, “more”]
Pipeline
Often a single data transformation operation is not enough. For example, if we want to create a sentiment classifier, we will need additional transformers. We mentioned earlier that ML.NET allows chaining multiple data transformers.
Let’s investigate a basic text transformation strategy.
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromEnumerable<SentimentModel>(inMemoryArray);
var pipeline = mlContext.Transforms.Text.NormalizeText("NormalizedSentiment", "Review", keepPunctuations: false)
.Append(mlContext.Transforms.Text.TokenizeIntoWords("Tokens", "NormalizedSentiment"))
.Append(mlContext.Transforms.Text.RemoveDefaultStopWords("NoStopWords", "Tokens"))
.Append(mlContext.Transforms.Conversion.MapValueToKey("Values", "NoStopWords"));
var preview = pipeline.Fit(data).Transform(data).Preview();This pipeline starts by taking the “Review” column as input. Normalizes the text and copies the result to a newly created column called “NormalizedSentiment”.
Next, “NormalizedSentiment” column serves as an input to TokenizeIntoWords method which creates an array of words and places them in the “Tokens” column.
Words like “a”, “the”, “is”, “are”, “and” are called stop words. Natural Language Processing (NLP) is a field where stop words needs to be eliminated. This is because they carry very little useful information.
Consider a scenario where you want to classify a single sentence as positive or negative.
Words like “great”, “excellent”, “amazing” carry information that the machine learning model can use and deduct that the sentence provided is most likely a positive one.
On the other hand, words like “and”, “a”, “is” etc. do not carry any useful information. As a result, we need to remove them.
RemoveDefaultStopWords is a method that enables you to filter out commonly used words in the English language.
Machine Learning algorithms cannot understand text. Nor it can understand array of words. Consequently, we must convert our data from text to vectors that our machine learning/deep learning algorithms can understand.
MapValueToKey does exactly that. It assigns unique numeric values to each word.
Transform Data in ML.NET: Text
If we have the following sentence:
I've been trying to learn C# Razor Pages, and this has been very helpful.
And we apply the Normalize Text method the output would be:
ive been trying to learn c razor pages and this has been very helpful
Next, we extract the words, and we are getting an array of type String, containing all the words
[ ive, been, trying, to, learn, c, razor, pages, and, this, has, been, very, helpful ]
Next operation removes the Stop Words from this array, and we are left with
[ ive, trying, learn, c, razor, pages, helpful ]
This is a good input array for the machine learning model. It only contains words that carry value, and they are standardized. But, like we said ML.NET algorithms don’t work with text, they work with numeric values. So, the last transformation we are going to apply is to map these word values to unique numeric keys.
[ 107, 9, 6, 7, 108, 109, 110 ]
Usually, the enumeration starts with one. But because this is just one random data point from the dataset, ML.NET assigns the first available number to the word that has no information on.
In our case that is the word “ive”. It is assigned the value of 107. Because the word “learn” has been used in other statements found in the dataset, its value is 6.
Now this is a numeric vector that we can pass to the learning algorithm. Each word is encoded into a numeric value. As a result, now the learning algorithm understands the input.
In the background ML.NET creates something like a look up table. So, if you want to reverse this vector into a string array this can be done very easily.
Here is a preview of the final result

Transform Data in ML.NET: Investigate Results
Sometimes you might want to print out the results, or even save and serialize them to disk. ML.NET offers a way to do that.
var transformedData = pipeline.Fit(data).Transform(data);
var dataPoints = mlContext.Data.CreateEnumerable<TransformedData>(preview, reuseRowObject: false);
Instead of calling the Preview method we simply execute the transformation. Remember you can only use the Preview method for debugging purposes only.
ML.NET provides a method to convert the IDataView into a strongly typed IEnumerable<T>. As a result, we introduce a new type called “TransformedData”. Let’s check the implementation:
public class TransformedData
{
[ColumnName("Review")]
public string Original { get; set; }
[ColumnName("NormalizedSentiment")]
public string Text { get; set; }
[ColumnName("Tokens")]
public string[] Tokens { get; set; }
[ColumnName("NoStopWords")]
public string[] NoStopWords { get; set; }
[ColumnName("Values")]
public UInt32[] Values { get; set; }
}
This type holds the result from all the steps we took to transform the data. It has the Original content, the Normalized content, the words array and ultimately the numeric array holding the unique word mappings.
Conclusion
This article demonstrates how to transform data in ML.NET. This framework provides various transformers for different types of scenarios.
Most of the machine learning applications require the creation of pipeline. Method chaining the data transformers allows a good coding structure and code maintainability.
Data is messy and chaotic. As a result, it must be transformed. Because, if the data is fed directly to machine learning algorithms it will leave the algorithm confused.
Make sure you process the data properly, before passing it forward.
Remember “Garbage In, Garbage Out”.
Now we know how to load and transform data in ML.NET. The next article will cover the training process. We will see what it is, and what it does, and how to use the Machine Learning algorithms ML.NET has already in store for us.
Previous Post: How to load data in ML.NET
Next Post: How to Train ML.NET Model
Project download link link: