
How to implement K-Means Elbow Method.
Source Code Link: Elbow Method Project Files
K-Means Elbow Method is a heuristic used in determining the number of clusters in a data set.
A lot of the tutorial/articles I am writing on this blog are related to K-Means clustering. One of the major decisions we have to make is how many clusters our data set have?
K-Means Clustering
K-means is a simple unsupervised machine learning algorithm that groups data into a specified number (k) of clusters. Because the user must specify in advance what k to choose, the algorithm is somewhat naive – it assigns all members to k clusters even if that is not the right k for the dataset.
Sometimes choosing the right number for k is not that simple. More often than not analyzing the dataset before hand is a must.
There are multiple articles using K-Means algorithm on this blog:
and although these are fairly simple problems to solve, you can still run the K-Means Elbow Method to determine the number of clusters in the dataset.
To complete this article you can use my K-Means implementation provided with this project, or you can use a third-party library such as Accord.NET and you can use the following K-Means implementation.
K-Means Elbow Method
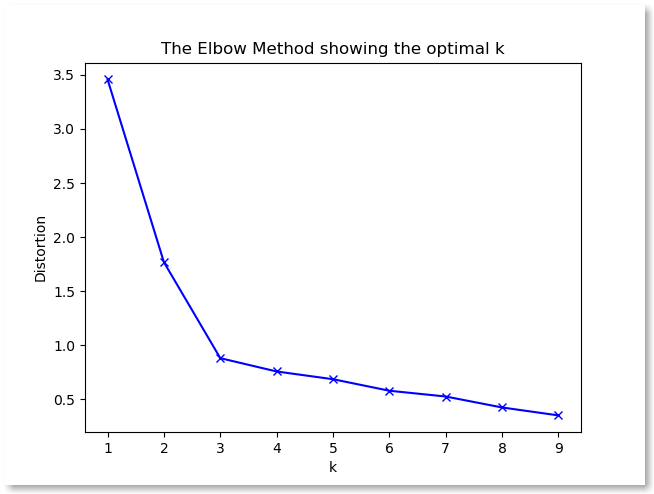
The elbow method runs k-means clustering on the dataset for a range of values for k (say from 1-10) and then for each value of k computes an average score for all clusters.
When these overall metrics for each model are plotted, it is possible to visually determine the best value for k. If the line chart looks like an arm, then the “elbow” (the point of inflection on the curve) is the best value of k. The “arm” can be either up or down, but if there is a strong inflection point, it is a good indication that the underlying model fits best at that point.
K-Means Elbow Method – Intuition
The intuition is that increasing the number of clusters will naturally improve the fit (explain more of the variation), since there are more parameters (more clusters) to use, but that at some point this is over-fitting, and the elbow reflects this.
This means that you should choose a number k so that adding another cluster doesn’t give much better modelling of the data.
In this scenario the intuition of over-fitting is expressed by subdividing the labeled groups into multiple clusters. Therefore, once the number of clusters exceeds the actual number of groups in the data, the added information will drop sharply, because it is just subdividing the actual groups.
Analyzing the project

From the application we can see that we are clustering three distinct groups. We are running the Elbow Method algorithm 6 times (The value K gets values from 1 to 6). By now you should know that we are actually running the K-Means algorithm and setting the K to values from 1 to 6.
By plotting the results we can observe that the best value for K is 3. And this is the correct solution just by observing the dataset. If we set K=1 then we can see the error is pretty big. For K=2 we can observe that the error decreased.
If we increase the number K (number of clusters) to 4,5,6 we can detect no changes in accuracy. The problem with higher number is that eventually these clusters will be divided into sub groups and the error rate will decrease even more.
To avoid that from happening we are plotting the results and using the “elbow” as a cut off point to choose a K where diminishing returns no longer worth the additional cost.
Also worth mentioning is that in practice there may not be a sharp elbow (like the one I provided) and such “elbow” cannot always be unambiguously identified.
Code Sample
for (int k = (int)start.Value; k <= (int)end.Value; k++)
{
List<double[]> distanceResult = new List<double[]>();
_kMeans = new KMeans(k, eucledeanDistance);
Centroid[] centroids = _kMeans.Run(trainingSetList.ToArray());
double result = 0;
foreach (double[] point in trainingSetList)
{
double minValue = Double.MaxValue;
foreach (Centroid centroid in centroids)
{
double distance = eucledeanDistance.Run(point, centroid.Array);
if (distance < minValue)
minValue = distance;
}
result += minValue;
}
result /= trainingSetList.Count;
}