
Today we are going to learn how to scrape web page using C#.
Full Source Code is available at
https://github.com/DevInDeep/WebScraperTool
What is Web Scraping
Web scraping refers to the process of extracting data from websites.
For example, if you find an article on Wikipedia that you find interesting, you can simply copy-paste the desired paragraph. That is data extraction. It’s simple and easy enough.
But what if you want to download large amounts of data? I am talking about a huge amount, that simply can not be process by hand. In situation like this, you need automation.
Web scraping is an automatic method to obtain large amounts of data from websites. But most of this data is unstructured. It is presented in a HTML format. Scraping is a process where unstructured data is converted into a structured spreadsheet or database.
There are many ways of performing this operations. Many modern websites offers an API. But, other don’t. This can be due to various reasons. In this particular case, you might want to use Web Scraping tool to get to the desired data.
Web Scraping tool in C#
In this tutorial we are going to scrape information from Wikipedia. To be more precise, we are going to find out which NBA franchise has the most championships.
To do that we must first enumerate all NBA teams. Then, for each team we need to find out the number of championships.
A quick search on Wikipedia lends us on the following page.
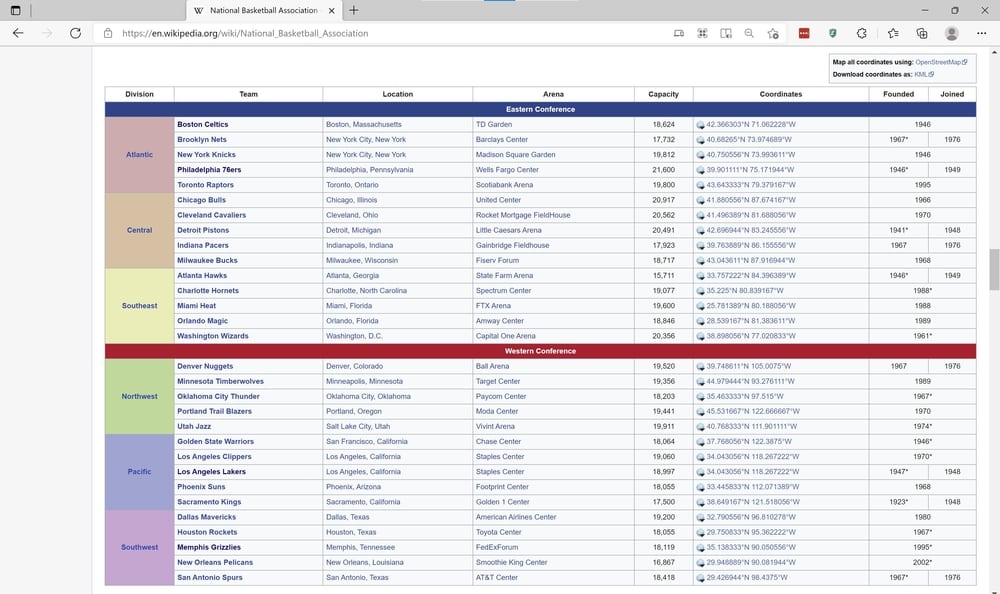
This table is exactly what I was hoping to find. A table with all NBA Teams currently playing in the league. But even better, there is a link that navigates me to the corresponding NBA Team Wikipedia page.
The Wikipedia page for the Boston Celtics looks something like this
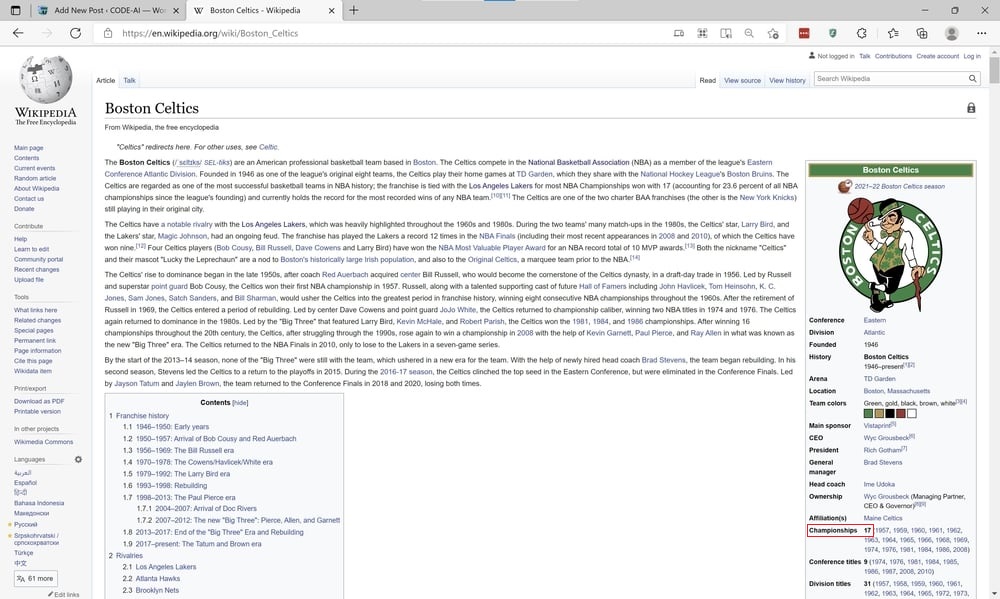
This page contains how many championship titles the team has won. Currently Boston Celtics and Los Angeles Lakers are tied at 17.
This is the application we are going to code today. We are going to scrape all the data for each individual NBA Team. Look at their the number of championships won, and answer the question: “Which team has won most titles in the NBA League?”
If you already know the answer to the question, of course you can simply navigate to the teams page and scrape the number only. Or maybe even create a list of pages to scrape, and return the club with most trophies. But, for demonstration purposes we are going to go the long way round.
So let’s get started.
Create new project
The first step is to create a brand new project. I will be using a Console Application built under the .NET Framework. Of course, my language of choice is C#.
Set the project name to: WebScraperTool or however you want to call it. But, because we want to learn how to scrape web page using C#, it is an appropriate name. I will be working with .NET 4.7.2
Install HtmlAgilityPack
In order to successfully scrape data of a web page using C#, we need to parse it first. HtmlAgilityPack is an HTML parser that will allow us to read data from the web page DOM by using XPath.
XPath on the other hand allows us to navigate through element nodes in HTML structured documents. As a result, we will be able to pinpoint particular piece of data, by combining these two technologies together.
But first, let’s install HtmlAgilityPack via NuGet Package Manager.
In your Visual Studio project from the main menu select Tools -> NuGet Package Manager -> Manage NuGet Packages for Solution…
A new Window will pop up.
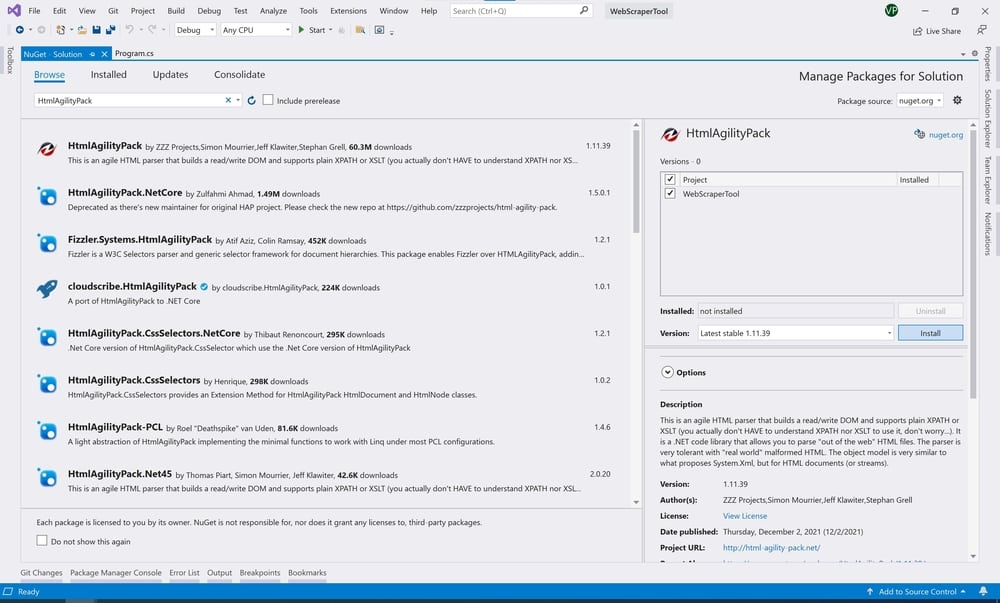
Navigate to the Browse tab and search for: HtmlAgilityPack. Select your project where you want to reference the library and click Install. That’s it.
We are ready to start coding the web scraper.
Coding the Web Scraper in C#
The only thing I want this program to do (for now) is display the team with the most NBA Championships. So, I will start my coding session like so:
static void Main(string[] args) =>
Console.WriteLine($"The team with most NBA Championships is: {GetBestNbaTeam()}");Next, we want to implement the GetBestNbaTeam method. But before we do that I want to add a model. This model will hold data related to the NBA team. So, create a new class called NbaTeam and paste or write up the following code segment
public class NbaTeam
{
public string Name { get; } = string.Empty;
public int Championships { get; }
private NbaTeam(string name, int championships)
{
this.Name = name;
this.Championships = championships;
}
public override string ToString() => $"{Name} {Championships}";
public static NbaTeam Create() => new NbaTeam(string.Empty, 0);
public static NbaTeam Create(string name, int championships) => new NbaTeam(name, championships);
}Scrape Web Page using C#
With this out of the way, we can start coding our method. This is where the query logic will reside, so we will go slowly and step by step.
The first obstacle we need to cross is downloading the web page source code. To do that, we will use the WebClient. In order to use it, we must reference the appropriate namespace
using System.Net;Now we can start writing GetBestNbaTeam method
static NbaTeam GetBestNbaTeam()=>
new WebClient().DownloadWebPage(new Uri("https://en.wikipedia.org/wiki/National_Basketball_Association"))If you have done everything by now, you will notice the compiler indicates that DownloadWebPage method doesn’t exist. So let’s add it.
Extensions Methods
Please note that this method will be an extension method to the WebClient class. In order to create it, we must first add a new class called WebClientExtensions.
Extension methods always live within a static class. So mark the class as static. Then, add the following using statements
using System;
using System.Net;
using HtmlAgilityPack;We need System.Net in order to use the WebClient class, and we also need to reference HtmlAgilityPack to use the HTML parser.
public static HtmlNode DownloadWebPage(this WebClient webClient, Uri uri)
{
var htmlSourceCode = webClient.DownloadString(uri);
var htmlDocument = new HtmlDocument();
htmlDocument.LoadHtml(htmlSourceCode);
return htmlDocument.DocumentNode;
}This method simply downloads the web page source code as a string. Then it loads it up into a HtmlDocument class and we are returning an HtmlNode.
We are coding like this because it simply makes sense. I want the client code to be able to execute XPath queries against the HTML document. So, let’s see it in action.
If we return back into our Program.cs file we can start writing expression to retrieve/scrape data from the web page. But, before we do that, let’s see what we actually want to scrape.
Scrape the NBA Teams Wiki Page
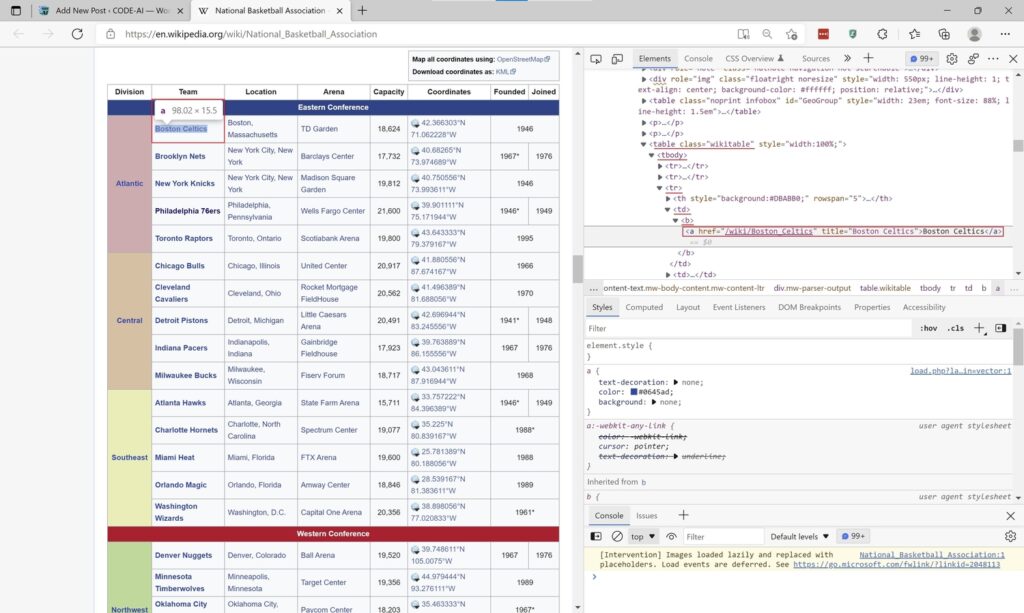
If we inspect the Table element in our Browser, we can clearly see that the table is uniquely identified via the class attribute. So, we want to navigate to a table element that contains attribute class with value wikitable.
Next, we want to move on to the body and find a row element with the following structure: td element that hosts a child element b.
By searching for this pattern, we will avoid the header rows. For example, the first row contains columns like: Division, Team, Location and so on. We also have a row with a single column splitting the table into conferences: East and West. Well, we don’t want that and using this pattern we will avoid it, simply because it doesn’t match to the structure we are searching for.
Now, let’s translate everything we talked about into code
SelectNodes("//table[@class='wikitable']/tbody//tr/td/b")As expected, since we are looking for all the teams, we are using the SelectNodes method. Inside the string literal we have written down the path pattern we want XPath to match.
It is a good idea to encapsulate away this string literal. You can place it into a more descriptive string variable. It will allow the code reader better understand what you are trying to do here.
Scrape Team Name and Team Wikipedia URL
We are trying to get to the b (Bold) element of the DOM because, it contains the name of the team, as well as the URL to the Wikipedia page as well.
What we need to do next is to scrape the fields we are interested in, and place them into our NbaTeam model.
Before we continue with the code example, please note that we will be using LINQ extensively. So let’s reference the namespace
using System.Linq;Now we can code the rest of our method. If we did not reference the LINQ namespace, we would be unable to use the Select and Aggregate methods.
.Select(teamNode =>
NbaTeam.Create(
teamNode.InnerText,
new WebClient().DownloadWebPage(new Uri(CreateUrl(teamNode.SelectSingleNode("a").Attributes["href"].Value)))
.SelectSingleNode("//th[text()='Championships']/following-sibling::td/b").InnerText.ToInt()))Chances are that compiler is screaming with errors. But bare with me for just a second.
Before we dig into explanation as to what this code does, we need to implement another method as well. The CreateUrl method
private static string CreateUrl(string partialUrl) => string.Format("{0}{1}", "https://en.wikipedia.org", partialUrl);If you inspect the URL value, the element is returning you will notice it is a partial one. It is missing “https://en.wikipedia.org” . Well, this method handles that scenario. So, don’t forget to include it in your code.
We can finally dive deep into explanation as to what this code does. Let’s start.
Scraping Championship Titles
Like we mentioned already, the first XPath expression returns a collection of HtmlNodes populated with the b (bold) element. This element contains the team name, as well as a child element a (anchor) that hosts href attribute, which points to the teams Wikipedia page.
So far, so good. This is exactly what we wanted to achieve. So, let’s extract the data.
To create a new instance of the NbaTeam data model we need to call the static constructor Create. It expects us to pass two parameters. The first one is the name of the team. The second one is the number of NBA Championship titles. Currently, we don’t have the number of championships.
But we do have the URL pointing to the tams web page. And we already know that the teams web page does contain the number of championships. As a result, we will download the HTML source code and write in an XPath expression to fetch the championships number.
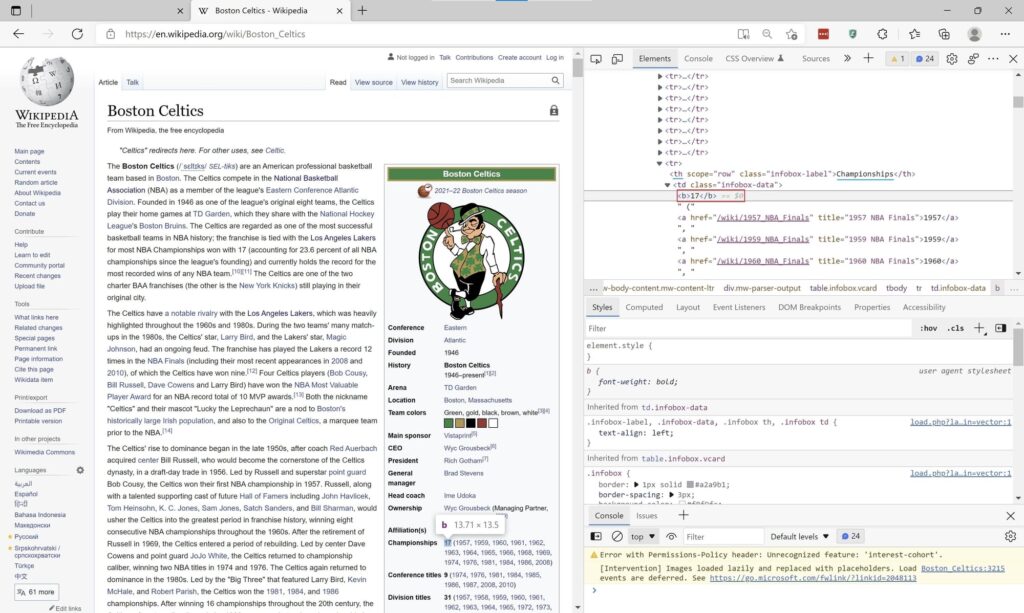
This time, we are looking for the HTML element th that contains the text Championships. Then we move to the following sibling which is the td element and fetch the b (Bold) element. Inside or the InnerText property of that element contains the number of championship titles. The XPath expression looks something like this
SelectSingleNode("//th[text()='Championships']/following-sibling::td/b").InnerText.ToInt()As you can see, this time we are looking for a single HtmlNode element. That is why we use SelectSingleNode method. The InnerText property returns a string. And we need an integer number. So let’s create another extension method to the string type.
Parsing the Web Scraped Data
Create a new class called StringExtensions. Implement it as static and paste the following code inside
public static int ToInt(this string value, int defaultValue = 0)
{
if (Int32.TryParse(value, out int result))
return result;
return defaultValue;
}This method is really easy to understand. If the string can be parsed as an integer, it will return the integer value. Otherwise, it will return the default value (which is set to 0). This is good for us, because there are teams in the NBA without any championship title. But they also have no championship information on their page. So the XPath expression will return an empty string. As a result, this function will return 0. Which is exactly what we wanted.
Finally, we can focus on finding the NBA franchise with most championship titles. To do that, we can sort by the number of titles and fetch the first item, but let’s use the aggregate function. It is way more performant then the sorting one.
Aggregate(NbaTeam.Create(), (best, next) => next.Championships > best.Championships ? next : best);Aggregate, returns the team who has won the most NBA trophies. It actually returns the NbaTeam data model. That class has override on the ToString() method. As a result, when this object is passed to the Console.WritelLine function it will simply call its ToString() and print all the information we need.
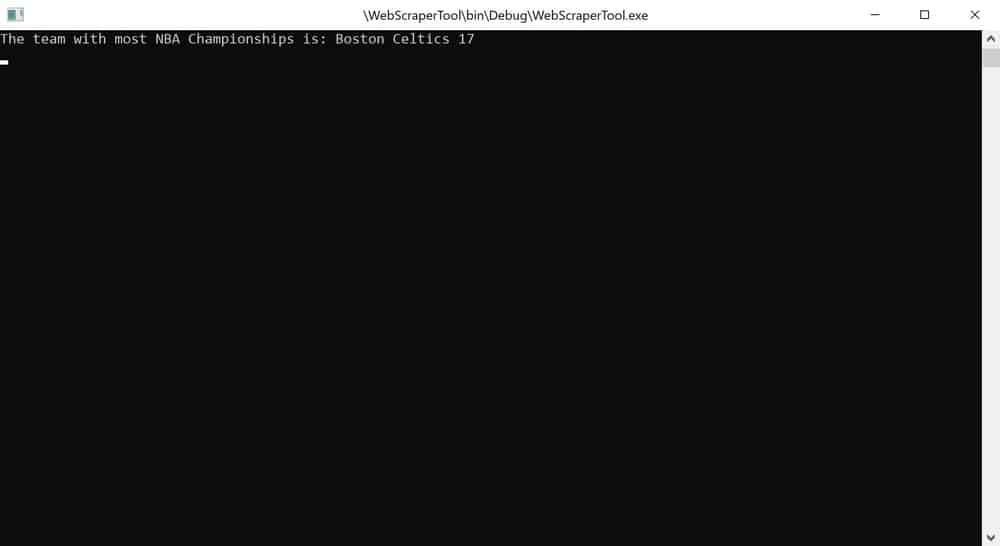
And the answer is pretty much what we expected. Except, Los Angeles Lakers also have 17 championship titles under their belt. This would be a good homework assignment if you want to extend this application.
Scrape Web Page using C#: A Conclusion
As you can see C# is pretty powerful and versatile language. Although, a lot of scrapers have been built in Python, you can see that this is possible in C# as well. This is only the beginning of the web scraping tutorial series. Next, we will introduce AI. We will implement Named Entity Recognition and Classification using C# and ML.NET.
So stay tuned…
More DevInDeep Tutorials:
- Introduction to Machine Learning in C#
- Face Mask Detection using C#
- Text Detection using C#
- How to Create AutoComplete TextBox in C#